131 1300 0010
人工智能領域邊緣側的應用場景多種多樣,在功能、性能、功耗、成本等方面存在差異化的需求,因此一款優秀的人工智能邊緣計算平臺,應當具備靈活快速適配全場景的能力,能夠在安防、醫療、教育、零售等多維度行業應用中實現快速部署。
百度大腦EdgeBoard嵌入式AI解決方案,以其豐富的硬件產品矩陣、自研的多并發高性能通用CNN(Convolution Neural Network)設計架構、靈活多樣的軟核算力配置,搭配移動端輕量級Paddle Lite高效預測框架,通過百度自定義的MODA (Model Driven Architecture)工具鏈,依據各應用場景定制化的模型和算法特點,向用戶提供高性價比的軟硬一體的解決方案,同時和百度大腦模型開發平臺(AIStudio、EasyDL)深度打通,實現模型的訓練、部署、推理等一站式服務。
EdgeBoard是基于Xilinx 16nm工藝Zynq UltraScale+ MPSoC的嵌入式AI解決方案,采用Xilinx異構多核平臺將四核ARM Cortex-A53處理器和FPGA可編程邏輯集成在一顆芯片上,高性能計算板卡上搭載了豐富的外部接口和設備,具有開發板、邊緣計算盒、抓拍機、小型服務器、定制化解決方案等表現形態。
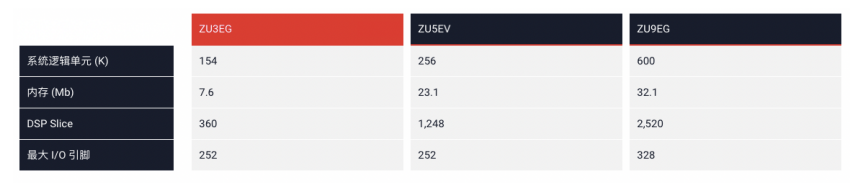
EdgeBoard計算卡產品可以分為FZ9、FZ5、FZ3三個系列,是基于Xilinx XCZU9EG、XAZU5EV、XAZU3EG研發而來,分別具有高性能,視頻硬解碼,低成本等特點,同時還有不同的DDR容量版本。以上三個版本PS側同樣采用四核Cortex-A53 、雙核Cortex-R5、以及GPU Mali-400MP2等處理器配置,PS到PL的接口均為12x32/64/128b AXI Ports,主要的區別在于PL側擁有的芯片邏輯資源大小不同,可參見下表。
采用上述三種標準產品的硬件板卡或者一致的硬件參考設計,用戶可無縫適配運行EdgeBoard公開發布的最新版標準鏡像,也可根據自身項目需求定制相關的硬件設計,并進一步根據性能、成本和功耗要求,以及其他功能模塊的集成需求,對軟核的算力和資源進行個性化配置。(多款開發板適配視頻教程:https://ai.baidu.com/forum/topic/show/957750)
2.1 CNN加速軟核的整體設計框架
EdgeBoard的CNN加速軟核(整體的加速方案稱之為軟核)提供了一套計算資源和性能優化的AI軟件棧,由上至下分別包括應用層軟件API、計算加速單元的SDK調度管理、Paddle Lite預測框架基礎管理器、Linux操作系統、負責設備管理和內存分配的驅動層和CNN算子的專用硬件加速單元,用來完成卷積神經網絡模型的加載、解析、優化和執行等功能。
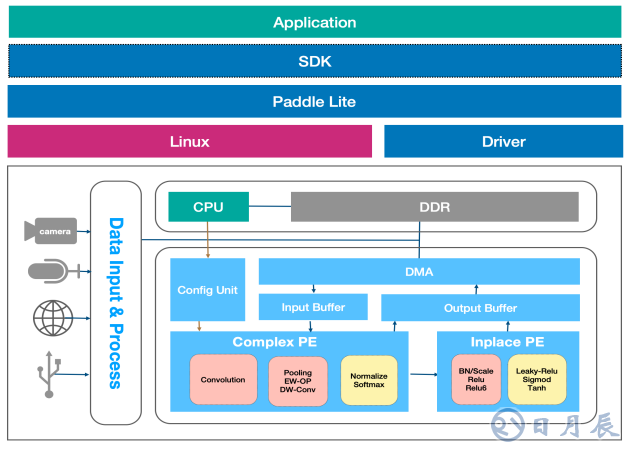
這些主要組成部分在軟件棧中功能和作用相互依賴,承載著數據流、計算流和控制流。基于上圖設計框架,EdgeBoard的AI軟件棧主要分為4個層次:
應用使能層
面向用戶的應用級(APP)封裝,主要是面向計算機視覺領域提供圖像處理和神經網絡推理的業務執行API。
執行框架層
Paddle Lite預測框架提供了神經網絡的執行能力,支持模型的加載、卸載、解析和推理計算執行。
調度使能層
SDK調度使能單元負責給硬件派發算子層面的任務,完成算子相應任務的調度、管理和分發后,具體計算任務的執行由計算資源層啟動。
計算資源層
專用計算加速單元搭配操作系統和驅動,作為CNN軟核的計算資源層,主要承載著部分CNN算子的高密度矩陣計算,可以看作是Edgeboard的硬件算力基礎。
2.2 CNN算子的加速分類
專用計算加速單元基于FPGA的可編程邏輯資源開發實現,采用ARM CPU和FPGA共享內存的方式,通過高帶寬DMA(Direct Memory Access)實現二者數據的高速交互,共享內存也并作為異構計算平臺各算子數據在CPU和FPGA協同處理的橋梁,減少了數據在CPU與FPGA之間的重復傳輸。此外,CNN算子功能模塊可直接發起DDR讀寫操作,充分發揮了FPGA的實時響應特性,減少了CPU中斷等待的時間消耗。
根據CNN算子的計算特點,EdgeBoard的算子加速單元可劃分為如下兩類:
復雜算子加速單元
顧名思義,是指矩陣計算規則較為復雜,處理數據量較多,由于片上存儲資源限制,通常需要多次讀寫DDR并進行分批處理的算子加速單元。
(1) 卷積(Convolution):包含常規卷積、空洞卷積、分組卷積、轉置卷積,此外全連接(Full Connection)也可通過調用卷積算子實現。
(2) 池化(Pooling):包含Max和Average兩種池化方式。
(3) 深度分離卷積(Depth-wise Convolution):與Pooling的處理特點類似,因此復用同樣的硬件加速單元,提高資源利用率。
(4) 矩陣元素點操作(Element-wise OP):可轉換為特定參數的Pooling操作,因此復用同樣的硬件加速單元,提高資源利用率。
(5) 歸一化函數(L2-Normalize):擁有較高處理精度,且實現資源最優設計。
(6) 復雜激活函數(Softmax):與Normalize處理特點相似,復用同樣的硬件加速單元和處理流程,提高資源利用率。
通路算子加速單元
通路算子是指在復雜算子加速單元的計算數據寫回DDR的流水路徑上實現的算子,適合一些無需專門存儲中間結果,可快速計算并流出數據的簡單算子。
(1) 各類簡單激活函數(Relu, Relu6, Leaky-Relu, Sigmoid, Tanh):基本涵蓋了CNN網絡中常見的激活函數類型。
(2) 歸一化(Batch norm/Scale):通常用于卷積算子后的流水處理,也可支持跟隨在其他算子后的流水處理。
另外一種分類方式,是根據CNN網絡里的算子常用程度劃分為必配算子和選配算子,前者指CNN軟核必需的算子單元,通常對應大部分網絡都涉及的算子,或者是芯片資源消耗極少的算子;后者指CNN軟核可以選擇性配置的算子單元,通常是特定的網絡會有的特定算子。這樣劃分的好處是,用戶根據MODA工具鏈自定義選擇,減少了模型中無用算子造成的邏輯資源的開銷和和功耗的增加。
必配算子:Convolution, Pooling, Element-Wise, Depth-Wise Convolution, BN/Scale, Relu, Relu6
選配算子:Normalize, Softmax, Leaky-Relu, Sigmoid, Tanh
2.3 卷積計算加速單元的設計思路
作為CNN網絡中比重最大、最為核心的卷積計算加速單元,是CNN軟核性能加速的關鍵,也占用了FPGA芯片的大部分算力分配和邏輯資源消耗。下面將針對EdgeBoard卷積計算加速單元的設計思路進行簡要介紹,此章節也是理解CNN軟核算力彈性配置的技術基礎。
每一層網絡的卷積運算,有M個輸入圖片(稱之為feature map,對應著一個輸入通道),N個輸出feature map(N個輸出通道),M個輸入會分別進行卷積運算然后求和,獲得一幅輸出map。那么需要的卷積核數量就是M*N。
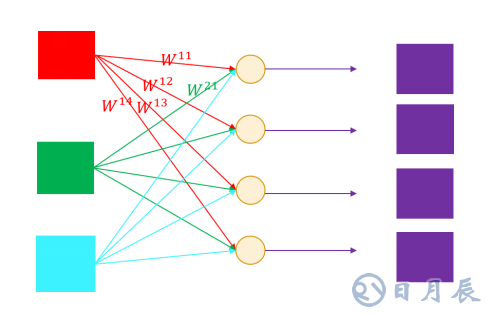
針對上述計算特點,EdgeBoard的卷積單元采用脈動陣列的數據流動結構,將數據在PE之間通過寄存器進行打拍操作,可以實現在第二個PE計算結果出來的同時完成和前一個PE的求和。這樣可以使數據在運算單元的陣列中進行流動,減少訪存的次數,并且結構更加規整,布線更加統一,提高系統工作頻率,避免了采用加法樹等并行結構所造成的高扇出問題。
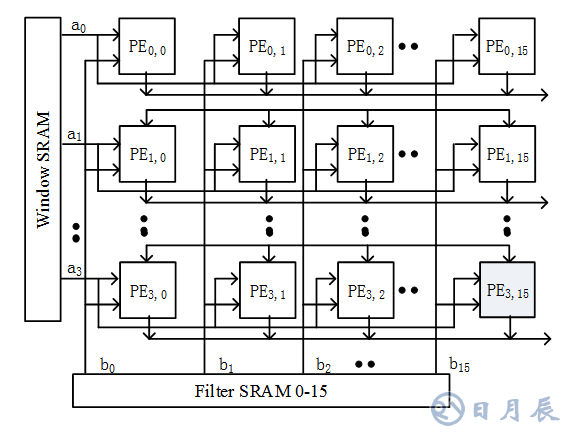
因此,如上圖所示,我們可以分別從Feature Map和Kernel兩個維度去定義脈動陣列的并行結構。從Feature Map的角度,縱向的行與行直接卷積窗口相互獨立,也就是輸出的每行之間所對應的數據計算互不干擾,在此維度定義的多并發計算稱之為Window維度的并行度。從Kernel的角度,為了達到計算結果的快速流出減少片上緩存占用,我們設計了每個Kernel核之間的多并發計算,稱之為Kernel維度的并行度。以上兩個維度同時并發既可以提高整體并行計算效率,也充分利用了脈動陣列的數據流水特性。
2.4 卷積計算加速單元的通用性擴展
前一章節詳細介紹了基于PL實現的卷積計算加速單元的設計原理,那么如果是由于芯片的SRAM存儲資源不夠而導致的CNN網絡參數支持范圍較小,EdgeBoard將如何拓展CNN軟核的網絡支持通用性? 我們可以利用靈活的SDK調度管理單元提前將Feature Map或者Kernel數據進行拆分,然后再執行算子任務的下發。
一條滑窗鏈的Feature Map數據不夠存儲
SDK可以將一條滑窗鏈的Feature Map數據分成B塊,并將分塊數B和每個塊的數據量告訴卷積計算加速單元,那么后者則可以分批依次從DDR讀取B次Feature Map數據,每次的數據量是可以存入到Image SRAM內。
Kernel的總體數據不夠存儲
SDK可以將Kernel的數量分割成S份,使得分割后的每份Kernel數量可以下發到PL側的Filter SRAM中,然后SDK分別調度S次卷積算子執行操作,所有的數據返回DDR后,再從通道(Channel)維度做這S次計算結果的數據拼接(Concat)即可。不過要注意的是,我們的Filter SRAM雖然不需存儲所有Kernel的數據量,但至少要保證能夠存儲一個Kernel的數據量。
由此看來,即使EdgeBoard三兄弟中最小的FZ3擁有極其有限的片上存儲資源,也是能夠很好地完成大多數CNN網絡的參數適配。
Edgeboard的CNN軟核除了公開發布的標準版本外,還可以由用戶根據自身模型需求和FPGA芯片選型,進行CNN卷積計算單元算力的定制化配置。配置算力的兩個關鍵指標包括Window維度并行度和Kernel維度并行度,具體含義可參考2.3章節,此處不再贅述。
我們以卷積計算加速單元的核心矩陣乘加運算消耗DSP硬核(Hard core)的個數作為CNN軟核核心算力的考察指標。當然,這并不包括卷積前處理、后處理模塊,以及其他算子加速單元或者用戶自定義功能模塊所消耗的DSP數量,因此這并不是整個解決方案在FPGA芯片內部的DSP資源消耗。我們的設計可以支持Window并行度1-8的任意整數,支持Kernel并行度包括4,8,16。具體的卷積雙維度配置組合所對應的核心DSP消耗可以參見下表。
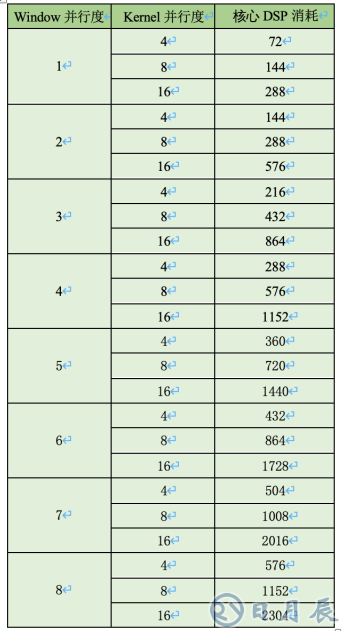
目前,EdgeBoard公開版針對卷積計算加速單元Window維度和Kernel維度的并行度配置,以及核心矩陣乘加運算的DSP硬核消耗可參見下表。
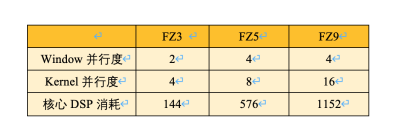
EdgeBoard的CNN軟核以其靈活的算力搭配組合以及算子可定制化的特點,既可以根據具體模型的算子組合和所占比例,將一定成本和資源條件內的芯片性能發揮到極致,還可以在滿足場景所要求性能的前提下減少不必要的功耗支出,此外還允許開發者縮減軟核尺寸并將芯片資源應用于自定義功能的IP中,極大地增強了EdgeBoard人工智能多場景覆蓋的能力。

