131 1300 0010
為何eFPGA比標(biāo)準(zhǔn)FPGA更高效?主要有如下三大原因。
原因1。如下圖,傳統(tǒng)FPGA構(gòu)架中,周圍的紅色邊框放置可編程I/O、高速SerDes及各種接口控制器,這些會占有30%~40%面積。如果做成嵌入式FPGA,這些面積可以省掉。下圖公式展示的FPGA和片芯面積的比例。

圖:核心電路與邊緣電路的比例
那么為何Speedcore比標(biāo)準(zhǔn)FPGA更高效?
原因2。微軟在其有關(guān)Catapulit項目(注:某云加速與計算項目)的白皮書中介紹了一種云規(guī)模的加速架構(gòu)。其中增加了一些術(shù)語,有shell(殼)和應(yīng)用。shell是I/O及電路板相關(guān)的邏輯電路,應(yīng)用是在核心邏輯上實現(xiàn)的核心應(yīng)用。
在此研究中,這些shell一旦固定到應(yīng)用中,這些可編程不能被可編程(即固定下來了)。另外,核心應(yīng)用是會改變的。因此如果拿掉shell,會節(jié)省44%的面積。

圖:如果去掉shell,會節(jié)省近一半的面積(注:左右兩圖的左上角均為“FPGA IO”)
原因3。在把shell剝?nèi)サ幕A(chǔ)上,又增加了自定義的custom block,這是由客戶自定義的,分布在speedcore架構(gòu)之中,有了這種custom block,面積會縮小75%,同時有更低功耗和更高的性能。
基于以上三個原因,即裁剪了FPGA的可編程I/O,shell資源去掉,另外提高了custom block,因此片芯面積大大縮減(如下圖)。
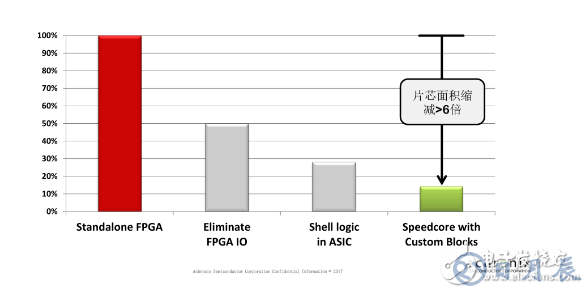
圖:與獨立FPGA相比,把Speedcore的三個優(yōu)勢
Achronix公司不久前推出的定制化的Speedcore custom blocks(定制模塊),可以實現(xiàn)最小的片芯面積,提供ASIC級的性能,去構(gòu)建獨立FPGA芯片無法提供的功能。
Achronix作為FPGA的后來者,今年也要跨入1億美元俱樂部。新產(chǎn)品Speedcore 推出一年已占營收1/4,未來三年將占半壁江山。在夾縫中生長,Achronix的商業(yè)模式就是不走尋常路。

