131 1300 0010
在這個移動設備成為主要計算平臺的大時代,稍微關注行業的人都聽說過ARM,該公司作為技術推動者,提供各種處理器架構以及核心參考設計,基本上已成為當今所有移動設備的動力之源,并在過去的5~7年里,引領著智能手機和平板電腦SoC性能的飛速發展。
ARM的雄心遠遠超出了移動和嵌入式設備領域。從商業意義上來看,服務器和相關基礎設施等高端領域有著更大的利潤空間,對于像ARM這樣的公司來說,這是一個非常有利可圖的市場。
不過,盡管ARM在移動和嵌入式設備領域取得了巨大的成功,但迄今為止始終未能觸及更高性能產品的領域。
雖然在過去的十年中,許多關于“ARM將掀起服務器和基礎架構市場革命”的預言層出不窮,也有不同的供應商試圖實現這一目標,然而前幾代產品并沒有獲得成功,ARM的服務器生態系統也遇到了相當大的困難。

服務器領域,多事之秋
去年年中,全新的Cortex A76架構橫空出世,ARM對其寄予厚望,以至于隨后公開分享了未來三年的CPU路線圖,并宣布將在PC筆記本電腦領域與Intel展開正面競爭。盡管驍龍8CX等產品的上市還需要等待很久,但外媒Anandtech已經拿到了首批搭載Cortex A76的移動設備,并驗證了ARM的所有性能和效率聲明。
最近,ARM又發布了新星架構Neoverse,并希望通過新一代處理器設計大幅提升其性能,并提高在服務器和基礎設施領域的競爭力。
這些新架構對ARM來說都很重要,它們代表了市場的一個轉折點:ARM處理器的性能表現已經接近了Intel和AMD處理器,且ARM有信心保持每年25~30%的性能提升,大幅超越Intel和AMD的迭代幅度。

過去幾個月對于ARM服務器生態系統來說是非常值得欣喜的。在去年的Hotchips大會上,富士通展示了全新的A64FX高性能計算處理器,不僅代表了公司從SPARC架構體系轉向ARMv8架構體系,還提供了第一款在ARM架構中實現新SVE(可擴展矢量擴展)的芯片。
Cavium的ThunderX2也取得了令人印象深刻的性能飛躍,使其新處理器成為首批能夠與Intel和AMD競爭的處理器。
前陣子,我們又看到了華為推出的全新鯤鵬920服務器芯片,該芯片有望成為業界性能最高的ARM服務器CPU。
上述三種產品之間最大的共性是,每種產品都代表了各供應商在實施基于ARMv8架構許可的定制微體系結構方面所做的努力。這實際上引出了一個問題:ARM自己的服務器和基礎設施市場計劃是什么?
此次,我們將詳細介紹Neoverse N1這個新平臺,它們將成為未來幾年ARM的基礎設施戰略的核心,并初步實現服務器生態系統。
Neoverse N1 CPU:無妥協性能
Neoverse N1平臺的核心是Neoverse N1 CPU,即CPU品牌與平臺品牌有相同的命名。ARM所描述的平臺不僅是CPU核心,還包括周圍的互連IP,使整個系統可以擴展到多核系統。

Neoverse N1平臺和CPU代表了ARM首款專為服務器和基礎設施市場設計的專用計算IP。這是對過去IP產品的重大改變,其中將為消費產品和行業解決方案提供相同的CPU IP。這些IP家族之間的新技術區別促使ARM為新的基礎架構目標產品采用新的營銷名稱,因此Neoverse品牌誕生,與面向消費者的Cortex CPU品牌區別開來。
Neoverse N1平臺代表了ARM奧斯汀設計中心“第二代奧斯汀家族”的第一次迭代。Neoverse N1原名為“戰神”,代表了與Cortex A76相對應的服務器處理器核心。同時,奧斯汀團隊可能已經完成了第二次迭代所需的Zeus架構的設計工作;隨后Poseidon架構將成為這一家族的最后一次迭代,然后將接力棒傳遞給由法國的索菲亞團隊設計的下一個架構家族。
由于Neoverse N1是Cortex A76架構的兄弟,兩款核心之間自然有很多相似之處。我們去年曾詳細介紹了Cortex A76架構,這些設計細節也同樣適用于Neoverse N1,二者僅在適應基礎設施用例方面有些差異。

就高層設計目標而言,ARM的目標似乎相當直接:創建一個毫不妥協的架構,并成為未來幾年內可重復使用的基礎。
特別值得一提的是,我們從Cortex A76上可以看出,ARM正在調整架構設計,使其能夠在基礎設施部署中以最高頻率運行。這與Intel和AMD在服務器CPU上采用的策略形成了鮮明的對比。
ARM在服務器CPU上的優勢在于可以同時優化性能、功耗和面積,而Intel和AMD不得不在這些指標中做出妥協,使其產品雖然與對應的消費級產品有著類似的架構,但頻率往往非常有限,這取決于給定的SKU針對的是哪個細分市場。
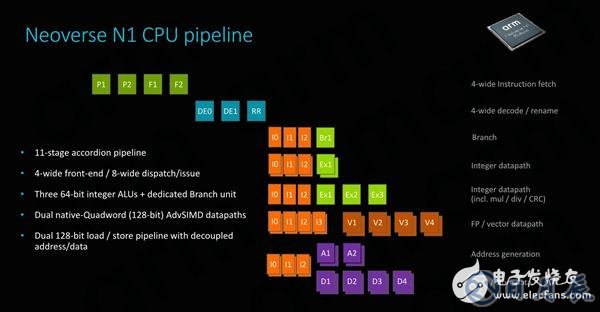
Neoverse N1的流水線結構與Cortex A76相同,均為11級短流水線設計,前端都是4寬的讀取/解碼器。ARM將其稱為“手風琴”管道,因為根據指令長度不同,它可以在延遲敏感的情況下將第二預測階段與第一獲取階段重疊,將調度階段與第一發布階段重疊,將流水線長度減少到9級。
執行后端也看起來與Cortex A76完全相同,擁有2個處理加減運算的簡單ALU、1個處理乘除運算的復雜ALU,以及2個處理向量和浮點運算的全寬128位SIMD流水線。
數據吞吐量是處理器架構的一項重要指標,ARM為Neoverse N1設計了兩個128位加載/存儲單元,能夠維持足夠的帶寬來提供和服務執行流水線。
架構前端與Cortex A76同樣非常相似,大容量的L1和L2具有低延遲訪問性能。這里的ARM還采用了業界公知的一些最大的分支目標和方向預測緩沖器,嘗試保持數據流經核心,并最小化分支預測和緩存命中失敗的概率來提高性能。

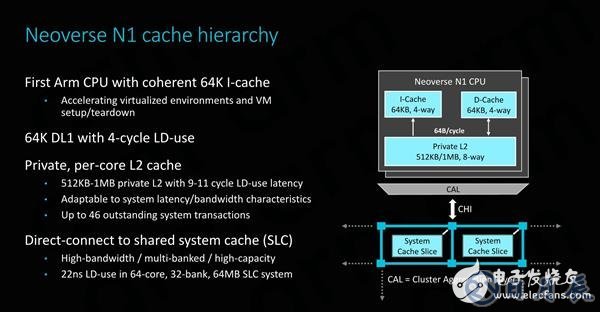
在緩存層次結構方面,Neoverse N1與Cortex A76相差很大。二者的L1緩存容量均為64KB,讀取延遲為4個周期,但是Neoverse N1上最大的不同在于緩存是完全一致的。
需要注意的是,硬件I-cache的一致性并不是ISA所要求的,到目前為止,通常都是通過軟件維護操作來完成的。
為N1實現硬件一致性對ARM來說非常重要,因為它極大地提高了性能并簡化了虛擬環境的實現,如果ARM想要在超大規模客戶中具有競爭力,就必須具備這些特性。擁有I-Cache的一致性被認為是一個關鍵的支持因素,可以使系統具有非常大的內核計數,ARM表示16核以上的系統都必須具備這一特性。
L2緩存可選擇512KB或1MB的配置,使用512KB配置時與Cortex A76基本相同,而1MB緩存則可以應對內存占用更大的應用程序。不過,將L2緩存加倍到1MB并不是沒有代價的,這會讓緩存的延遲增加2個周期,達到11個周期的負載使用延遲。
Neoverse N1與Cortex A76的一個很大的區別在于,在進行大尺度緩存操作時,Neoverse N1不會去尋找集群,而是會使用mash互聯的方式。
如圖所示,該連接首先通過一個CAL或組件聚合層。每個CAL最多支持兩個接口,這就是為什么我們在每個“集群”中只能看到兩個CPU(它本身并不是真正的集群)。然后CAL連接到網格的XP(交叉點),它本質上是網絡的交換機/路由器組件。每個XP都有兩個可用端口;在ARM參考設計示例中,第二個端口連接一個系統級緩存。
在64核系統搭配2MB系統級緩存的示例系統中,整個64MB緩存的平均負載使用延遲為22ns。ARM給出的延遲數據是納秒數而不是周期數的原因是系統級緩存和mesh運行在與CPU異步的頻率上,通常是內核頻率的2/3左右。
直接連接是Neoverse N1和CMN-600的一個整體特征。這個特性只存在于這個平臺上,而在Cortex架構上是不可能實現的。本質上,它刪除了DSU的所有L3和探聽過濾器邏輯,而是直接將CPU內核連接到CMN的CHI接口。因此,內存控制器和CPU核心之間的通信本質上只需要通過一個中間層,即mash網絡本身。
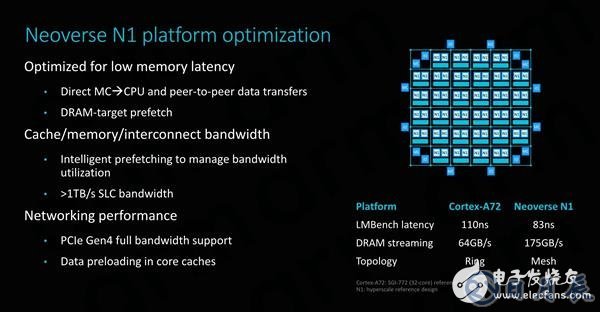
直接從內存控制器向CPU數據傳輸可能有點難以解釋,當CPU向內存控制器發出數據請求時,它能夠立即同時首先向其發送“預取”類型請求,同時通過mesh網絡中XP主節點的探聽過濾器正常傳輸命令,然后將請求路由到內存控制器。因此,內存控制器將提前知道請求的到來,并且已經開始獲取數據,從而隱藏部分有效的內存延遲,而不是整個傳輸按串行順序進行。
預取對整個系統的性能非常重要,智能管理數據預取可以有效優化系統級帶寬。據說在具有64核心和8個DDR4 3200內存通道的Neoverse N1參考系統中,可以實現高達175GB/s的內存帶寬。ARM還公布了延遲數據,但ARM的數據表示LMBench數據,同時配置了256MB測試深度的2MB大頁面。選擇大頁面可以減少TLB的遺漏,并更接近實際的內存延遲,這就是ARM在這種情況下發布度量的基本原理。
我們還沒有機會測試啟用了大頁面的競品系統,但是AMD的EPYC 7601(LRDIMM DDR4 2666 19-19-19)可在芯片的高速緩存層次結構的末端通過類似于LMBench的測試來實現約73ns的延遲,而定制開發的延遲測試將TLB失敗最小化后延遲約為57ns。Intel W-3175X(RDIMM DDR 2666 24-19-19)在相同測試下延遲分別為94ns和64ns。

使用臺積電7nm工藝制造的Neoverse N1芯片面積非常小,在使用512KB二級緩存時核心面積約為1.2平方毫米,與麒麟980所用Cortex A76的1.26平方毫米幾乎相同,將L2緩存加倍到1MB后,核心面積也只有1.4平方毫米。
在頻率范圍方面,ARM的設想是在0.75V電壓下達到2.6GHz,在1V電壓下可實現3.1GHz。在這條頻率曲線末端,提升44%的功耗只能得到19%頻率和性能提高,因此大多數供應商都希望更接近功率曲線中更有效的部分。
不過從絕對數字來看,Neoverse N1的功耗只有1~1.8W,這為64核SoC提供了充足的空間,ARM對于64核Neoverse N1參考設計的總功率預算約為105W。
Neoverse N1超大規模參考設計
ARM提供Neoverse N1的完整參考設計,其中包含一組完全由ARM自己驗證的IP。這套參考設計的目標是為供應商提供“甜點”配置選項,這樣他們就可以用相對最少的努力來實現最優的性能。
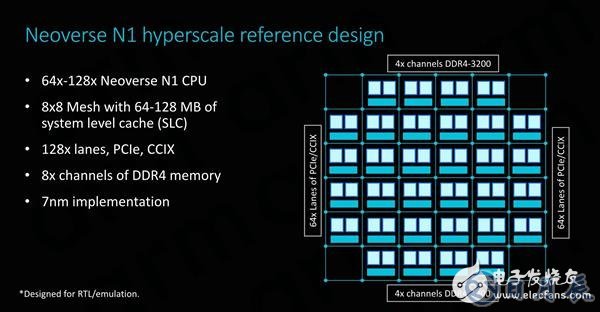
Neoverse N1的參考設計中可采用64或128核心配置,集成在具有64 MB或128MB 系統級緩存的CMN-600 mash網絡中。I/O接口方面,128條PCI-E 4.0通道分別用于I/O和CCIX接口,可提供足夠的I/O帶寬。
在內存方面,ARM為其配置了8通道DDR4控制器,最高支持3200MHz。不過實際上,ARM已經放棄了自行研發內存控制器,因為大多數情況下客戶會使用各自的內部設計,或者選擇從其他第三方供應商(如Cadence或Synopsys)處選擇方案。
對于目前的參考設計來說,ARM自己的DMC-520內存控制器仍然是最新的,且對于公司來說是一個很好理解的模塊。不過在未來,像DDR5這樣的較新的內存控制器也將不得不依賴于第三方IP。
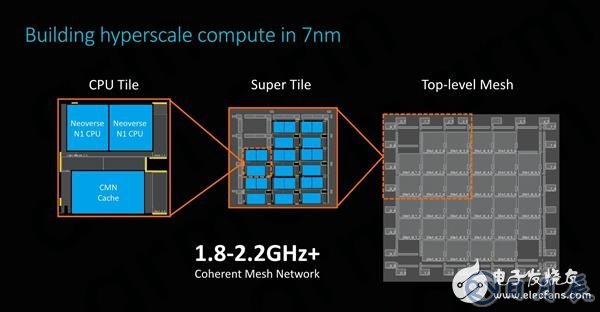
SoC的物理實現將使用便于設計的可復用分層構建塊。每個CPU模塊由兩個Neoverse N1內核、一組系統級緩存,以及CMN的交叉點和本地節點的一部分組成。通過翻轉和鏡像來復制CPU模塊,即可生成最終的SoC頂層網格。
在7nm工藝節點上,ARM的64核Neoverse N1參考設計搭配64MB高速緩存,芯片尺寸接近400平方毫米,可能略高于供應商想要的可制造性目標。為了緩解這種擔憂,ARM同時提出了小芯片設計的想法,讓多個小芯片通過CCIX鏈路進行通信,保證了必要的靈活性,供應商可自行決定如何設計解決方案。
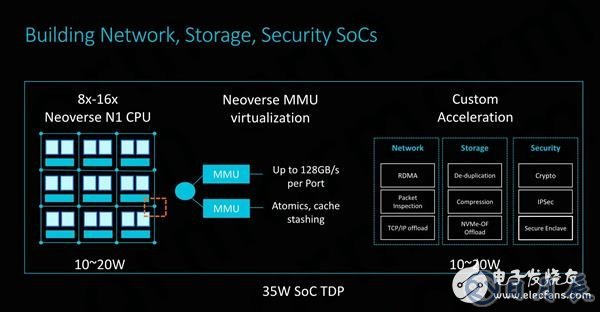
智能網卡的集成能力也是其設計和靈活性的一個重要方面,為了在大型系統中最大限度地提高計算能力,加速網絡連接實際上是在盡可能密集且有效的形式因素下實現高吞吐量的關鍵。
CMN-600允許在其交叉點上設置從端口,通過高達128GB/s的高帶寬總線與內存管理單元連接,可輕松外掛其他固定功能的硬件模塊。
CCIX對ARM非常重要,因為它使其產品組合能夠與第三方IP產品集成。 為外部IP模塊啟用高速緩存一致性是一個非常有吸引力的功能,因為它大大簡化了供應商的軟件設計。 基本上這意味著軟件只是看到一個巨大的內存塊,而非相干系統需要驅動程序和軟件知道并跟蹤內存的哪個部分是有效的,哪些不是。 在IP集成方面,ARM提供與CMN-600集成的CCIX一致網關,而另一方面,它是第三方IP提供商提供CCIX轉換層的責任。
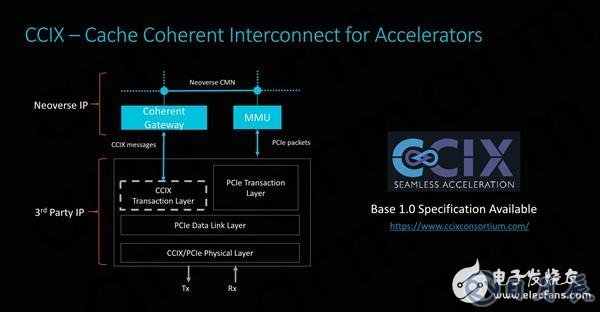
對ARM來說,CCIX非常重要,它可讓其產品組合能夠與第三方IP產品集成。為外部IP塊啟用緩存一致性是一個非常有吸引力的特性,可大大簡化供應商的軟件設計,不再需要系統、驅動和軟件跟蹤哪些是有效內存。在IP集成方面,ARM提供了與CMN-600集成的CCIX相干網關,而第三方IP提供商則提供CCIX翻譯層。
在芯片的邏輯設計中,供應商還必須設計一套健壯的配電網絡,以支撐實際使用情況中各種突發且嚴苛的電能需求。這對許多供應商而言都是一個非常頭疼的問題,因為設計需要復雜的模型,且在大多數情況下,配電網絡需要過度設計以提供穩定性保證,這反過來又增加了實施的復雜性和成本。

ARM旨在通過以專用微控制器的形式提供極細粒度的DVFS(動態電壓頻率調整)機制來緩解這些問題。控制器訪問CPU核心內部的詳細活動監視單元,查看實際有多少晶體管正在積極工作,并將此信息反饋給系統控制器以更改DVFS狀態。這使供應商能夠將其配電網絡設計為更保守的容差,從而節省實施成本。
性能預測
關于性能和效率的討論,必然需要用具體的數字來衡量。在ARM公布Neoverse N1時,大多數性能數據都是相對于Cortex A72的改進,這并沒有將Neoverse N1真正置于競爭格局中最相關的數據點。Cortex A72是一款2015年推出的架構,兩款產品之間有著3~4年的時間跨度。
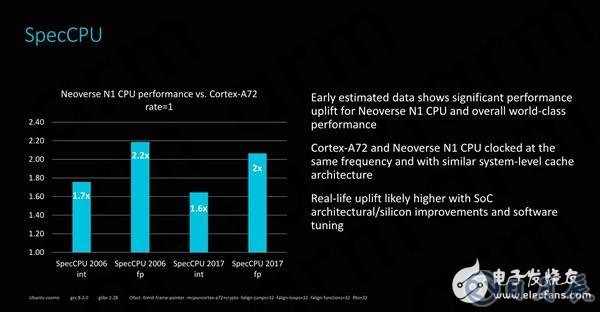
與相同頻率且同樣配有系統級緩存的Cortex A72平臺相比,全新的Neoverse N1平臺直接以碾壓的姿態獲得完勝。在SPEC的單線程測試中,Neoverse N1的整數運算PPC(每時鐘性能)和絕對性能相比Cortex A72增長了60%~70%,浮點運算性能則更令人印象深刻,增幅高達100%~120%。且鑒于Neoverse N1還有許多其他SoC級別的改進及軟件優化,實際的性能表現將會更高。
與現有解決方案相比,ARM再次迭代了非常大幅的性能演進,在向量工作負載中實現了超過2倍的性能提升。自然,Neoverse N1支持ARMv8.2指令集也意味著它支持8位點積和FP16半精度指令,這些指令特別適合機器學習工作負載,實現了比前一個平臺近5倍的性能提升。

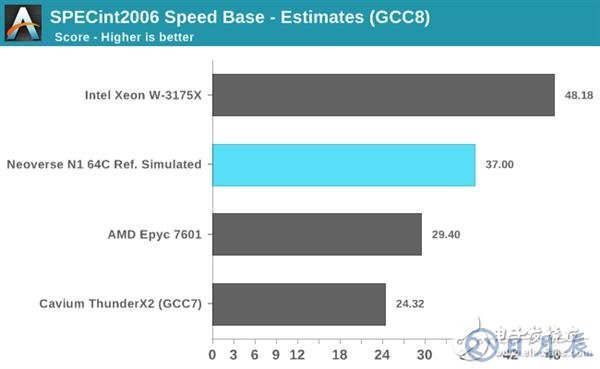
對于運行速度約為2.6GHz的64核Neoverse N1超大規模參考設計,在105瓦TDP下,其SPECint2006單線程得分約為37,而多線程得分預計約為1310。
不過這一性能不是在實際運行的產品上測出的,而是在ARM的服務器群上使用RTL模擬環境中估算出來的。

Neoverse N1的單線程得分,明顯高于在同源的Cortex A76上測量的26分,撇開軟件和編譯器的考慮不提,造成42%性能差異的原因之一可能是Neoverse N1擁有更好的內存和緩存系統,整個系統帶寬比Cortex A76這種移動SoC高6倍,在單線程工作負載中,線程可以完全訪問64MB系統級緩存,這比Cortex A76設計的L3緩存大16倍。
ARM強調,在改善生態系統性能的眾多努力中,除了提供更好的硬件之外,還需要提供更好的軟件。在過去的幾年里,ARM投入了大量精力來改進開源工具和編譯器,比如將最新版GCC9與舊版的GCC5進行比較,其整數和浮點工作負載的性能提高了13~15%,且這些優化是面向實際用例的改進,而不是旨在提升SPEC跑分的針對性的改變。
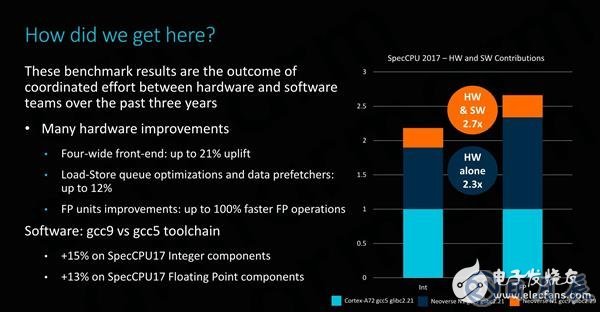
就單線程性能而言,Neoverse N1看起來非常出色,它以很大的優勢擊敗了目前性能最佳的ARM服務器CPU,即Cavium的ThunderX2。
既然是面向服務器領域的產品,免不了要與老牌供應商Intel和AMD進行對比,在Intel和AMD最新的、也是最好的Xeon W-3172X以及EPYC 7601上,同樣使用GCC8編譯一組二進制文件進行。
Intel的Xeon W-3172X很難說是最具代表性的超大規模CPU,但它4.5GHz的單核睿頻頻率可提供多核CPU中最強的單線程性能。 AMD的EPYC 7601則是一個更有代表性的數據點,其3.2GHz的頻率和Neoverse N1很有的比,實際成績來看也確實如此。
再來看SPECrate2006的多線程測試,這是所有平臺的最佳擴展場景,沒有序列化或線程間通信,測試套件只是并行運行多個進程。
從ARM給出的模擬測試結果來看,64核的Neoverse N1以105瓦的TPD實現了極高的性能和效率,x86解決方案甚至很難能夠競爭。

雖然測試比較的是64核ARM平臺與32/28核x86平臺,貌似使用AMD即將推出的64核Rome處理器才更公平,但從數據來看,即使AMD的64核處理器能實現目前雙倍的性能,其TDP也不太可能降低到Neoverse N1這樣105 瓦的水平(EPYC 7601的TDP 是180瓦)。
總結
Neoverse N1看起來是一款優秀的架構,它保持了ARM一貫領先的電源效率,實現了峰值計算性能和總體吞吐量之間的最佳平衡。
ARM對Neoverse N1及其最終的繼任者抱有很高的期望,希望從Intel等供應商中搶走x86處理器根深蒂固的市場份額。ARM正在盡最大努力,雖然Neoverse N1不會成為旗艦x86的核心競爭對手,但在可以輕松擴展到更多核心的工作負載中,它會構成重大威脅。
當然,在實際硬件產品出現之前,我們還不能下任何定論,但ARM此前對Cortex A76的性能預測非常符合實際設備上的測量結果,因此我們有理由給予Neoverse N1的性能預測以信任,實現預測中的性能肯定是有希望的。
盡管新的硬件IP令人印象深刻,但同樣重要的是ARM在加強ARM軟件生態系統方面的努力。與不同行業的硬件和軟件合作伙伴合作,試圖促進軟件堆棧和與ARM的互操作性,這不僅有利于使用ARM自己的硬件IP的供應商,而且有利于選擇使用自己的定制CPU和SoC設計的供應商。同樣,那些試圖改進和加強自己產品的供應商,也將反過來加強ARM的生態系統。本質上,這是許多公司之間的集體努力,未來將繼續獲得動力。

可以看出,ARM正非常認真地對待基礎設施建設,過去的一年對于ARM生態系統來說是革命性的,我們第一次看到了ARM廠商平臺與Intel和AMD等主流廠商競爭。雖然ARM沒有透露誰將首先使用Neoverse N1平臺的信息,但ARM正無可辯駁地成為行業主流。
據傳Neoverse N1將在未來12~18個月內進行商業部署,這將是ARM的關鍵時刻。如果一切進展順利,ARM和合作伙伴實現了承諾的改進,未來1~2年里,服務器行業必將迎來一次重大轉變。

